on
Quick guide to customize your resume for different machine learning roles
As a job seeker in the machine learning and data science field, the job search process is often confusing from the very start.
Data Scientist, Machine Learning Engineer, Data Analyst, Data Engineer, which one should you apply to?
I had been lost and confused about which roles to apply to during my job search as well. But now, after being in hundreds of machine learning interviews on both sides, I’ve found an effective approach to identify the right machine learning roles most suited for each job seeker to apply to, as well as how to tailor your resume to maximize your chances of getting interviews and offers.
I’ve refined my approach into 3 steps, and it has helped me land multiple Data Scientist job offers (at various levels), Machine Learning Engineer, and even a senior data science manager role. My goal is to share this process so you can do the same!
- Machine learning roles - what should you pick?
- 1. Take inventory of your past experience
- 2. Map your experience to ML skills matrix
- 3. Tailor your resume to your desired role(s)
- Additional notes
- Conclusion
Machine learning roles - what should you pick?
I went on LinkedIn at the time of writing this article and searched “spotify machine learning”.
The top results are for Machine Learning Engineer (MLE) and Data Scientist (DS), with those 2 roles showing up evenly in the top 10 results (left side of the screenshot only has the top 5 due to screen space). As I scroll on a bit more, there are backend engineer and data engineer roles as well.
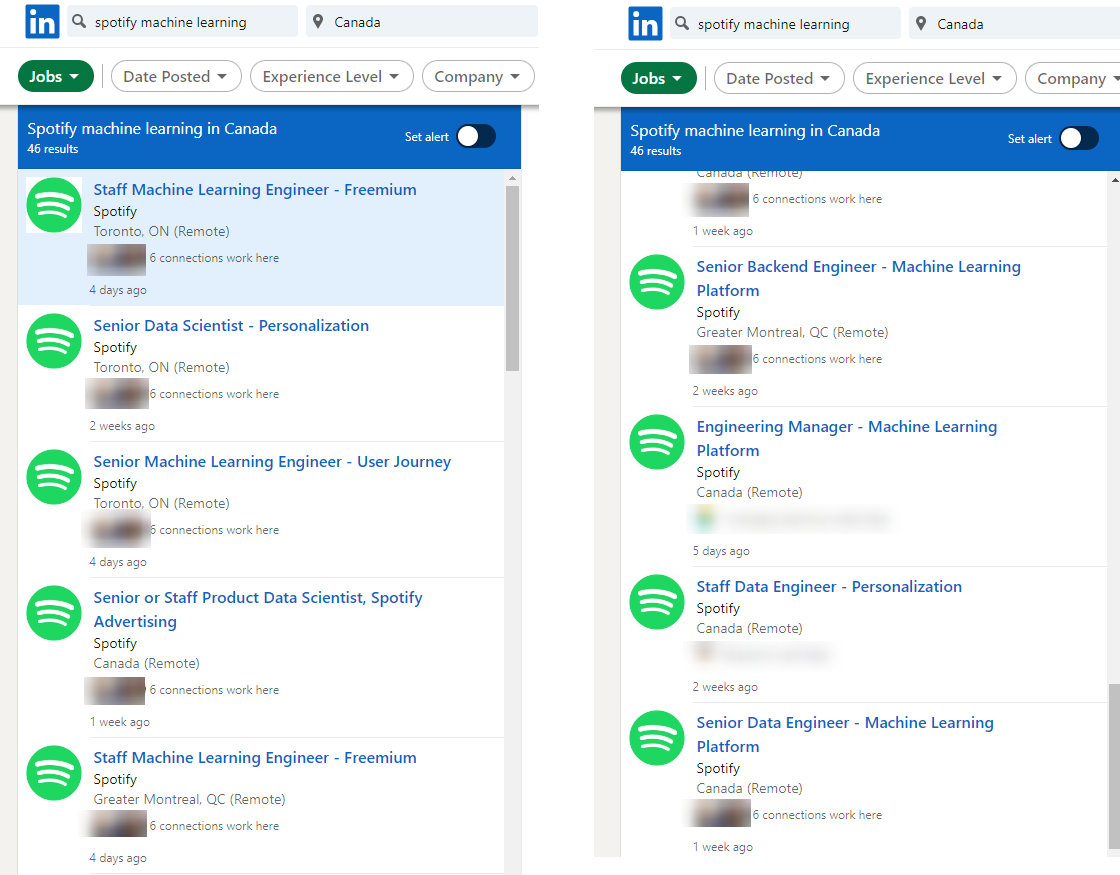
Searching for only “machine learning” yields “data scientist” and “machine learning engineer” being evenly represented in the top 4 results, and then “data engineer”.
How do you find out which job posting best suits your skills, especially if you are a new grad or transitioning careers? My formal education background was in economics, which made it even more confusing for me at the time.
If you’re in the same boat now, I’ve included my own new grad and economics student resume examples - if I could use those projects to enter the machine learning field and build a thriving career, so can you!
Next we’ll walk you through the 3 steps to identify roles for you, and tailor your resume for those roles.
I recommend reading all the following steps first to gain a quick overview, and then read a second time slower while following the instructions. Even if you already have a resume, you can see by the end of this article how to best frame it to the roles you’re interested in.
1. Take inventory of your past experience
Before even applying for a job, we’ll start with taking inventory of what you did in the past.
This inventory includes past work experience, machine learning projects at school or at work - anything that could be relevant to machine learning and data science.
Even if you’ve only had school projects or work experience outside of machine learning, you can still include it - after reading all the steps you’ll learn how to frame it to be relevant.
As an example, when I was a new grad (with under 1 year of working experience), my list looked like this:
- (University of Toronto) Econometrics research paper about video game prices on Steam, with data I scraped
- (University of Toronto) Econometrics research paper about Reddit engagement, with data I scraped myself
- (My first full time job) An ML churn model I built
List out “everything you did”
From the above list, pick up to 3 of them that you feel that are most relevant to machine learning roles in general. If you feel that you don’t have enough, you can pad with the work or school experiences you had the most responsibilities in.
Next, list out “everything you did” - which is not only technical or coding/ data related parts, but also “soft skills” such as presenting the results to your team or organizing a group chat to coordinate teammates.
New grad (< 1 year experience) example: My first ML churn model
- Exploratory data analysis (EDA) with SQL, Python
- Clean data with SQL
- Train model with SAS
- Run model evaluation and analyze results with SAS, SQL, Python
- Create simplified and cleaner visualization to use in presentation with Excel, PowerPoint
- Present the results with PowerPoint
- Collaborate with ML engineer to put the model in production
Economics student example: Econometrics research paper about Reddit engagement, with data I scraped myself
- Scraped Reddit with Python
- Cleaned data with Python
- Statistical modelling with Python, Stata
- Visualized results with Python
- Presented results with LaTeX
2. Map your experience to ML skills matrix
Remember the variety of roles that showed up when searching “machine learning” job postings?
Let’s cut through the noise so you can focus on marketing your skills to the roles that best fit your experience.
See the table below for a very broad strokes skills breakdown of each role:
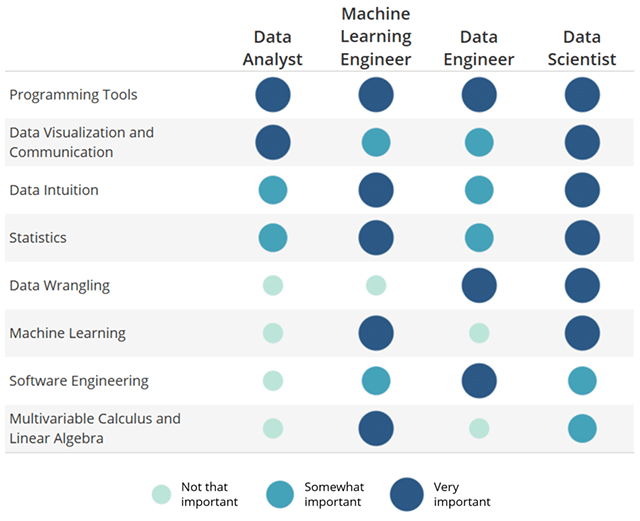 Source: Udacity
Source: Udacity
We can see right off the bat that Data Analyst can have an overlap with Data Scientist, which in turn overlaps a lot with MLE. The good news is that with a few of these skills in the skills list, you can apply to one or more of the roles.
But don’t worry - for entry level roles, as long as we have one or two of these skills, we’re good to go for applying to jobs. It’s also perfectly normal for new grads to have strong skills in one particular aspect but not all aspects, which employers fully understand and welcome.
However, mapping your skills to this matrix is only part of this entire process, because the reality is, this matrix has to be taken with a heavy dose of “it depends”. That’s why for the 3rd step, we’re ready to look at real job postings to apply to.
3. Tailor your resume to your desired role(s)
Alright, now we’re back to the job postings search engine of your choice! I personally like to start with LinkedIn, since I’m familiar with the platform, but most job are cross posted on major platforms anyway.
Based on the skills matrix, you can already see why tailoring your resume can be useful - if you have “programming tools” and “statistics” skills, you can possibly apply to DS and MLE, but in order to highlight additional skills that differ between the two roles, changing some bullet points would help market your skills better.
Remember how I said that for the ML skills matrix, “it depends”? It helps you narrow down titles that fit your past experience better, but you should still look into the jobs descriptions themselves.
Once you start to look at job posting descriptions, sometimes “Data Scientist” might involve skills that were mapped to data analyst (“Product” data science), and sometimes the job posting could map more to MLE on the matrix.
My personal experience of “it depends”: My job title has been Data Scientist for all of my full time roles, but I’ve always been focused on building and deploying machine learning models into a product, or improving the ML product. Based on the matrix, I’ve done everything from MLE, “Applied scientist”, and more.
Resume tailoring step by step example
You’re reading this article, but I’ll try to make it like a screensharing experience as if I’m browsing these jobs and you’re looking over my shoulder.
Now, I’m back to browsing the “spotify machine learning” search result from the beginning of this article, and start clicking into them.
Example 1: Data Scientist posting
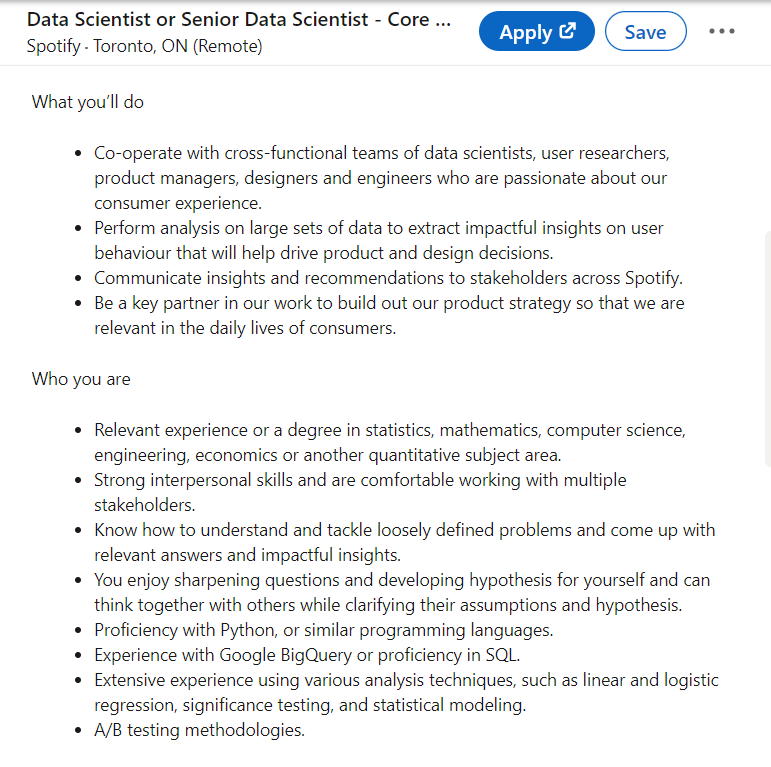
I read this Data Scientist posting, and write down what I think is important in it:
- Cooperation with stakeholders, communication (mentioned multiple times and are at the top of the bullet points)
- Perform data analysis, using BigQuery or SQL
- Some statistical modelling such as linear, logistic regression
Next, I’ll look back to the list of 7 points from “My first ML churn model!” example in Step 1, and map it to the Data Scientist posting.
The most relevant points are:
- Exploratory data analysis (EDA) with SQL, Python
- Create simplified and cleaner visualization to use in presentation with Excel, PowerPoint
- Present the results with PowerPoint
I’ll tailor my resume for this Data Scientist role focused on these points, and shorten or remove the other parts, so that it’s focused on those 3 bullet points instead of 7.
How much you’d remove depends on how much space you have on your resume! I have more experience now so I err on the side of removing, while early on I chose to pad more points.
It’s fine to remove things as long as the core is there; if the interviewers were interested in how I train more complex ML models - a bullet point I removed since it wasn’t on the job description, they can just ask me in the interview.
I’d then summarize those 3 points into even less bullet points, while keeping the information, such as “Churn predictive modelling to optimize campaign targeting for customer retention, and explainability analysis for stakeholders to understand the model interpretation [SAS language, Python, SQL]”.
Example 2: Machine learning engineer job posting

Now, I read this Machine Learning Engineer (MLE) posting, and write down what I think is important in it:
- Implementing ML in production
- Prototyping
- Testing and tooling, platform improvements
- Collaboration with cross functional teams
Next, I’ll look back to the list of 7 points from “My first ML churn model!” example in Step 1, and map it to the MLE posting.
The most relevant points are:
- Train model with SAS
- Run model evaluation and analyze results with SAS, SQL, Python
- Collaborate with ML engineer to put the model in production
- Clean data with SQL
With the same experience, for different job requirements, I now have different bullet points that were grabbed from the same skills inventory I did in Step 1. For job-seekers that are looking for their very first MLE role, I also recommend reading this book, “Designing Machine Learning Systems” by Chip Huyen (I own a physical copy) to get a sense of the skills that are needed for the MLE role.
The best part is, the inventory from Step 1 can simply be reused for different types of roles without needing to re-write anything.
As an aside: Communication and collaboration skills are important, and you’ll notice them listed a lot in all types of job postings. Don’t forget to include the points where you were collaborating with other teams, or presenting your work to another organization in at least one of your resume points.
This is especially relevant for folks that think they don’t have enough “ML experience”! Your experience analyzing data, as well as communicating it, is important and can strengthen your resume more than you might think.
Next steps
Now, you’ve learned how to identify the machine learning roles best suited for you, and you’re ready to create a set of tailored resumes for each type of role.
Now, you might be thinking - it’s too much work to tailor for every single job posting there is! To which I agree, and here’s how I optimize the use of tailored resumes:
- I look at more job postings, find what suits me and interests me the most, and note down what they have in common. The types of “Data Scientist” roles I’m interested in could be very different from “Data Scientist” roles that interests another job seeker.
- I try to create 2-3 tailored resumes that I can send out en masse to roles that need similar skills, such as to DS or MLE that requires more MLOps knowledge, and another that is more analytics focused.
- For jobs I’m very very interested in, I build off those tailored resumes and fine-tune them for each job post. This is not a waste of my time and has yielded a very high call-back rate for me.
Additional notes
The power of resume customization
By the time I graduated from my economics master’s program, I had a job offer as a Data Scientist, and at the same time, a job offer for PM at Ubisoft - two very different types of roles, in very different industries. With the same student project experiences, just written and framed differently in my tailored resumes.
Make your own experience
When I was a new grad, I lacked ML “deployment” experience, but I saw it on many job postings, so I wanted that on my resume. After serving a machine learning model in a web app in my own side project, I put it on my resume and voila, I was getting multiple interviews for senior roles (one even flew me from Toronto to San Francisco).
I’ve written about how to pick a data science project that stands out on your resume in this article.
Conclusion
In this article we looked at different types of machine learning roles, how to take inventory of your past experiences, and then tailor the way you present your resume based on those job postings.
This creates a powerful career story that is much more effective than sending the same resume for all machine learning roles. While this helps especially for new grads and for career transitions, it can be helpful for current data professionals looking to specialize or move to a different role.
I hope that you’ve found any point helpful, and if you know anyone that would benefit from this, please share it with them! If you’d like to ask more questions that I can elaborate on in a future article, feel free to reach me at hello@susanshu.com or message me on LinkedIn.